

This started with one of our Talent Acquisition specialists requested a list of previously asked interview questions. The objective was to prevent redundancy in later interview stages. This raised an intriguing challenge: how could we systematically capture and structure these interactions in a way that is both scalable and privacy-conscious?
As both COO and engineer, I saw an opportunity to develop an AI-driven solution while ensuring strict data security. Since external AI services were not an option due to data sensitivity, the solution had to be self-hosted or at least minimize exposure through controlled cloud environments.
A Three-Phase Implementation Strategy
I structured the development process into three distinct phases:
Establishing a foundational script for diarization and transcription.
Implementing a system where file uploads trigger processing pipelines.
Creating a user-friendly UI that facilitates query-based interactions with transcripts.
Evaluating Self-Hosted AI Solutions
After extensive research, I identified the most suitable frameworks for speaker diarization and transcription:
pyannote-audio (Optimal for Speaker Diarization)
Strengths: Cutting-edge speaker recognition.
Weaknesses: Requires a Hugging Face pretrained model.
Deployment: Python-based, GPU-recommended, integrates with Whisper and Vosk.
Whisper + pyannote-audio (Balanced Hybrid Approach)
Utilizes Whisper for transcription and pyannote for speaker segmentation.
Aligns timestamps between transcription and diarization.
NVIDIA NeMo ASR + Speaker Diarization
Strengths: High accuracy, GPU acceleration, trainability.
Weaknesses: Complex setup, requires NVIDIA GPU.
Kaldi + Vosk (Lightweight, CPU-Compatible Alternative)
Strengths: Operates efficiently on low-resource systems.
Weaknesses: Lower diarization accuracy.
Initial Experimentation: Whisper + pyannote-audio
My initial approach employed Whisper + pyannote-audio to process interview recordings. However, I encountered a fundamental issue:
Diarization output:
- start: 8.41784375
end: 10.645343750000002
speaker: SPEAKER_02
- start: 13.817843750000002
end: 15.876593750000001
speaker: SPEAKER_01
- start: 23.85846875
end: 24.75284375
speaker: SPEAKER_03
- start: 28.48221875
end: 29.02221875
speaker: SPEAKER_06
- start: 28.54971875
end: 28.684718750000002
speaker: SPEAKER_05
- start: 32.49846875
end: 46.96034375
speaker: SPEAKER_01
- start: 48.141593750000006
end: 48.158468750000004
speaker: SPEAKER_01Transcription output:
- text: ' So that, for example, if I am on the A, I will suppose I have gone through
all the E so that I will not prefix it again with forage. So I will do set minus
one, for example. And here I will see if map.getc is greater than minus one. But
why? You already aggregated this data.'
start: 263.433
end: 291.125
- text: ' Yes, so suppose I am going through each of these strings again.'
start: 291.732
end: 295.158
- text: ' So, I will see that post A. No, no, please stop. It''s important, very important
stuff. The first part is... Oh, right. The collection, right? If you have a collection,
why should you mutate this collection? This collection purpose is only to get
the result string, but... You''re right, you''re right.'
start: 296.086
end: 322.175Since Whisper does not produce precise word-level timestamps, mapping text to individual speakers was unreliable, leading to overlapping segments and misattributions. This resulted in transcripts where multiple speakers' statements were incorrectly merged, making it difficult to extract meaningful dialogues and speaker-specific insights. Without accurate timestamps, diarization lacked the necessary precision to be useful in practical scenarios, requiring an advanced alignment method to improve reliability. This necessitated a more advanced alignment method.
Solution: WhisperX
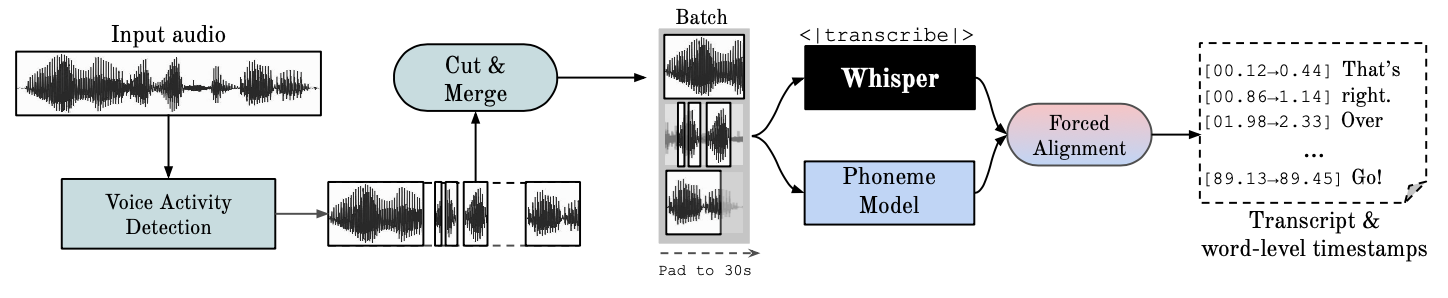
Subsequent research led me to WhisperX, which augments Whisper’s transcription capabilities through phoneme detection and forced alignment. This additional layer of processing ensures that words receive accurate timestamps, enabling precise speaker segmentation.
WhisperX’s pipeline visualization:
Development Environment
Operating System: Windows 11 (WSL2)
GPU: Nvidia GeForce GTX 1060 (6GB, CUDA-enabled)
Programming Expertise: Limited Python experience but sufficient for experimentation
Execution of the Proof of Concept (PoC)
Once configured, my implementation followed these steps:
Place
input.wavin./input.Execute
python runall2.py.Extract the structured output
transcription.csvfrom./output.
Here is the full code: https://github.com/valor-labs/ai-transcriptionI’m not a Python developer, so I hope you will excuse me for the code. It’s quite simple, you’ll see.
device = "cuda"
batch_size = 2
compute_type = "int8" # "float32"
model_dir = "./model/"
HF_TOKEN = os.getenv("HUGGINGFACE_TOKEN")print(f"{elapsed()} 1. Loading model and audio")
model = whisperx.load_model("turbo", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx.load_audio(audio_file)
print(f"{elapsed()} 2. Load Whisper model and transcribe")
transcription_results = model.transcribe(audio, batch_size=batch_size)print(f"{elapsed()} 3. Align transcription")
model_a, metadata = whisperx.load_align_model(language_code=transcription_results["language"], device=device)
alignment_results = whisperx.align(transcription_results["segments"], model_a, metadata, audio, device, return_char_alignments=False)print(f"{elapsed()} 4. Speaker diarization")
diarize_model = whisperx.DiarizationPipeline(use_auth_token=HF_TOKEN, device=device)
diarization_results = diarize_model(audio)print(f"{elapsed()} 5. Assigning words to speakers")
result = whisperx.assign_word_speakers(diarization_results, alignment_results)
pprint.pprint(result["segments"][:4], depth=2)print(f"{elapsed()} 6. Process and format the output")
structured_output = []
current_speaker = None
current_start = None
current_end = None
current_text = []
def format_time(seconds):
return str(timedelta(seconds=int(seconds)))
for segment in result["segments"]:
speaker = segment.get("speaker", "UNKNOWN_SPEAKER")
start = segment.get("start", "unknown")
end = segment.get("end", "unknown")
text = segment.get("text", "")
if speaker != current_speaker:
if current_speaker is not None:
structured_output.append([current_speaker, format_time(current_start), format_time(current_end), " ".join(current_text)])
current_speaker = speaker
current_start = start
current_text = [text]
else:
current_text.append(text)
current_end = end
if current_speaker is not None:
structured_output.append([current_speaker, format_time(current_start), format_time(current_end), " ".join(current_text)])print(f"{elapsed()} 7. Save to CSV")
with open(final_output_path, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Speaker", "Start", "End", "Speech"])
writer.writerows(structured_output)
print(f"{elapsed()} Transcription saved to {final_output_path}")Debug Efficiency
To enhance debugging efficiency, I saved intermediary results in YAML or binary formats. This allowed specific steps to be skipped using command-line flags:
--skip-whisper: Loads existing WhisperX transcription.--skip-alignment: Skips forced alignment.--skip-diarization: Uses precomputed diarization data.
Resolving Technical Challenges
CUDA Public Key Mismatch
Issue: Failed GPU initialization due to outdated CUDA installation and mismatched repository keys.
Solution: Resolved by updating CUDA packages using
sudo apt update && sudo apt upgrade, manually importing the correct public key with: + ---- wget -qO- https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub | sudo apt-key add - ---- and ensuring PyTorch and CUDA versions are correctly aligned usingnvcc --versionandtorch.cuda.is_available().
Excessive Processing Time
Issue: Processing a 60-minute file exceeded acceptable time limits.
Solution: Optimized batch sizes, implemented efficient GPU memory management, and leveraged mixed-precision computation. Additionally, experiment with switching between
int8andfloat32precision to balance performance and quality.int8can significantly accelerate inference on compatible hardware while reducing memory usage, though it may slightly degrade accuracy. If high fidelity is required,float32remains the preferred choice. As a next step, leveraging powerful cloud-based GPU instances could further enhance performance and scalability, reducing processing time while handling larger workloads. I will cover this in detail in the next article.
Future Directions
Pending further internal validation—such as accuracy benchmarks, processing efficiency, and user feedback—and demonstrated public interest through engagement and adoption, the next iterations will focus on:
Cloud Deployment: Enabling automated file processing with real-time results.
Web-Based UI: Providing an interactive interface for transcript analysis.
Sentiment & Emotion Detection: Expanding capabilities to include speaker tone and engagement analysis.
This project has provided valuable insights into AI-powered transcription and diarization. In the upcoming article, I will explore the complexities of cloud deployment and scaling this solution for broader usability.
If you have thoughts, feedback, or experiences to share, I’d love to hear them!


